1、前馈神经网络(FFNN)
前馈神经感知网络与感知机(FF or FFNN:Feed forward neural networks and P:perceptrons)非常简单,信息从前往后流动(分别对应输入和输出)。
一般在描述神经网络的时候,都是从它的层说起,即相互平行的输入层、隐含层或者输出层神经结构。单独的神经细胞层内部,神经元之间互不相连;而一般相邻的两个神经细胞层则是全连接(一层的每个神经元和另一层的每一个神经元相连)。一个最简单却最具有实用性的神经网络由两个输入神经元和一个输出神经元构成,也就是一个逻辑门模型。给神经网络一对数据集(分别是“输入数据集”和“我们期望的输出数据集”),一般通过反向传播算法来训练前馈神经网络(FFNNs)。
这就是所谓的监督式学习。与此相反的是无监督学习:我们只给输入,然后让神经网络去寻找数据当中的规律。反向传播的误差往往是神经网络当前输出和给定输出之间差值的某种变体(比如MSE或者仅仅是差值的线性变化)。如果神经网络具有足够的隐层神经元,那么理论上它总是能够建立输入数据和输出数据之间的关系。在实践中,FFNN的使用具有很大的局限性,但是,它们通常和其它神经网络一起组合成新的架构。
Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
http://www.ling.upenn.edu/courses/cogs501/Rosenblatt1958.pdf
2、径向基神经网络(RBF)
径向神经网络(RBF:Radial basis function)是一种以径向基核函数作为激活函数的前馈神经网络。没有更多描述了。这不是说没有相关的应用,但大多数以其它函数作为激活函数的FFNNs都没有它们自己的名字。这或许跟它们的发明年代有关系。
Broomhead, David S., and David Lowe. Radial basis functions, multi-variable functional interpolation and adaptive networks. No. RSRE-MEMO-4148. ROYAL SIGNALS AND RADAR ESTABLISHMENT MALVERN (UNITED KINGDOM), 1988.
http://www.dtic.mil/cgi-bin/GetTRDoc?AD=ADA196234
3、霍普菲尔网络(HN)
霍普菲尔网络(HN:Hopfield network)是一种每一个神经元都跟其它神经元相互连接的网络。
这就像一盘完全搅在一起的意大利面,因为每个神经元都在充当所有角色:训练前的每一个节点都是输入神经元,训练阶段是隐神经元,输出阶段则是输出神经元。
该神经网络的训练,是先把神经元的值设置到期望模式,然后计算相应的权重。在这以后,权重将不会再改变了。一旦网络被训练包含一种或者多种模式,这个神经网络总是会收敛于其中的某一种学习到的模式,因为它只会在某一个状态才会稳定。值得注意的是,它并不一定遵从那个期望的状态(很遗憾,它并不是那个具有魔法的黑盒子)。它之所以会稳定下来,部分要归功于在训练期间整个网络的“能量(Energy)”或“温度(Temperature)”会逐渐地减少。每一个神经元的激活函数阈值都会被设置成这个温度的值,一旦神经元输入的总和超过了这个阈值,那么就会让当前神经元选择状态(通常是-1或1,有时也是0或1)。
可以多个神经元同步,也可以一个神经元一个神经元地对网络进行更新。一旦所有的神经元都已经被更新,并且它们再也没有改变,整个网络就算稳定(退火)了,那你就可以说这个网络已经收敛了。这种类型的网络被称为“联想记忆(associative memory)”,因为它们会收敛到和输入最相似的状态;比如,人类看到桌子的一半就可以想象出另外一半;与之相似,如果输入一半噪音+一半桌子,这个网络就能收敛到整张桌子。
Hopfield, John J. “Neural networks and physical systems with emergent collective computational abilities.” Proceedings of the national academy of sciences 79.8 (1982): 2554-2558.
https://bi.snu.ac.kr/Courses/g-ai09-2/hopfield82.pdf
4、马尔可夫链(MC)
马尔可夫链(MC:Markov Chain)或离散时间马尔可夫链(DTMC:MC or discrete time Markov Chain)在某种意义上是BMs和HNs的前身。可以这样来理解:从从我当前所处的节点开始,走到任意相邻节点的概率是多少呢?它们没有记忆(所谓的马尔可夫特性):你所得到的每一个状态都完全依赖于前一个状态。尽管算不上神经网络,但它却跟神经网络类似,并且奠定了BM和HN的理论基础。跟BM、RBM、HN一样,MC并不总被认为是神经网络。此外,它也并不总是全连接的。
Hayes, Brian. “First links in the Markov chain.” American Scientist 101.2 (2013): 252.
http://www.americanscientist.org/libraries/documents/201321152149545-2013-03Hayes.pdf
5、玻尔兹曼机(BM)
玻尔兹曼机(BM:Boltzmann machines)和霍普菲尔网络很接近,差别只是:一些神经元作为输入神经元,剩余的则是作为隐神经元。
在整个神经网络更新过后,输入神经元成为输出神经元。刚开始神经元的权重都是随机的,通过反向传播(back-propagation)算法进行学习,或是最近常用的对比散度(contrastive divergence)算法(马尔可夫链用于计算两个信息增益之间的梯度)。
相比HN,大多数BM的神经元激活模式都是二元的。BM由MC训练获得,因而是一个随机网络。BM的训练和运行过程,跟HN大同小异:为输入神经元设好钳位值,而后让神经网络自行学习。因为这些神经元可能会得到任意的值,我们反复地在输入和输出神经元之间来回地进行计算。激活函数的激活受全局温度的控制,如果全局温度降低了,那么神经元的能量也会相应地降低。这个能量上的降低导致了它们激活模式的稳定。在正确的温度下,这个网络会抵达一个平衡状态。
Hinton, Geoffrey E., and Terrence J. Sejnowski. “Learning and releaming in Boltzmann machines.” Parallel distributed processing: Explorations in the microstructure of cognition 1 (1986): 282-317.
https://www.researchgate.net/profile/Terrence_Sejnowski/publication/242509302_Learning_and_relearning_in_Boltzmann_machines/links/54a4b00f0cf256bf8bb327cc.pdf
6、受限玻尔兹曼机(RBM)
受限玻尔兹曼机(RBM:Restricted Boltzmann machines)与BM出奇地相似,因而也同HN相似。
它们的最大区别在于:RBM更具实用价值,因为它们受到了更多的限制。它们不会随意在所有神经元间建立连接,而只在不同神经元群之间建立连接,因此任何输入神经元都不会同其他输入神经元相连,任何隐神经元也不会同其他隐神经元相连。
RBM的训练方式就像稍微修改过的FFNN:前向通过数据之后再将这些数据反向传回(回到第一层),而非前向通过数据然后反向传播误差。之后,再使用前向和反向传播进行训练。
Smolensky, Paul. Information processing in dynamical systems: Foundations of harmony theory. No. CU-CS-321-86. COLORADO UNIV AT BOULDER DEPT OF COMPUTER SCIENCE, 1986.
http://www.dtic.mil/cgi-bin/GetTRDoc?Location=U2&doc=GetTRDoc.pdf&AD=ADA620727
7、自编码机(AE)
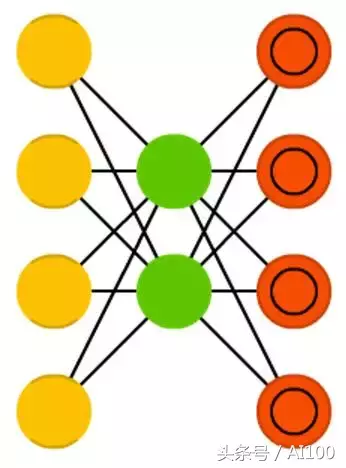
自编码机(AE:Autoencoders)和FFNN有些相近,因为它更像是FFNN的另一种用法,而非本质上完全不同的另一种架构。
自编码机的基本思想是自动对信息进行编码(像压缩一样,而非加密),它也因此而得名。整个网络的形状酷似一个沙漏计时器,中间的隐含层较小,两边的输入层、输出层较大。自编码机总是对称的,以中间层(一层还是两层取决于神经网络层数的奇偶)为轴。最小的层(一层或者多层)总是在中间,在这里信息压缩程度最大(整个网络的关隘口)。在中间层之前为编码部分,中间层之后为解码部分,中间层则是编码部分。
自编码机可用反向传播算法进行训练,给定输入,将误差设为输入和输出之差。自编码机的权重也是对称的,因此编码部分权重与解码部分权重完全一样。
Bourlard, Hervé, and Yves Kamp. “Auto-association by multilayer perceptrons and singular value decomposition.” Biological cybernetics 59.4-5 (1988): 291-294.
https://pdfs.semanticscholar.org/f582/1548720901c89b3b7481f7500d7cd64e99bd.pdf
8、稀疏自编码机(SAE)
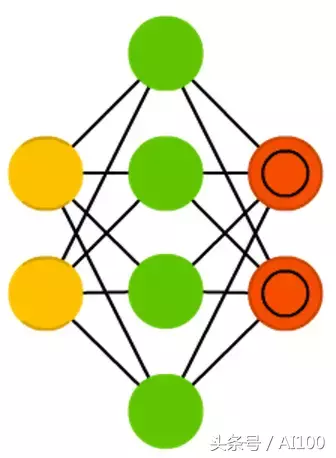
稀疏自编码机(SAE:Sparse autoencoders)某种程度上同自编码机相反。稀疏自编码机不是用更小的空间表征大量信息,而是把原本的信息编码到更大的空间内。因此,中间层不是收敛,而是扩张,然后再还原到输入大小。它可以用于提取数据集内的小特征。
如果用训练自编码机的方式来训练稀疏自编码机,几乎所有的情况,都是得到毫无用处的恒等网络(输入=输出,没有任何形式的变换或分解)。为避免这种情况,需要在反馈输入中加上稀疏驱动数据。稀疏驱动的形式可以是阈值过滤,这样就只有特定的误差才会反向传播用于训练,而其它的误差则被忽略为0,不会用于反向传播。这很像脉冲神经网络(并不是所有的神经元一直都会输出)。
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra, and Yann LeCun. “Efficient learning of sparse representations with an energy-based model.” Proceedings of NIPS. 2007.
https://papers.nips.cc/paper/3112-efficient-learning-of-sparse-representations-with-an-energy-based-model.pdf
9、变分自编码机(VAE)
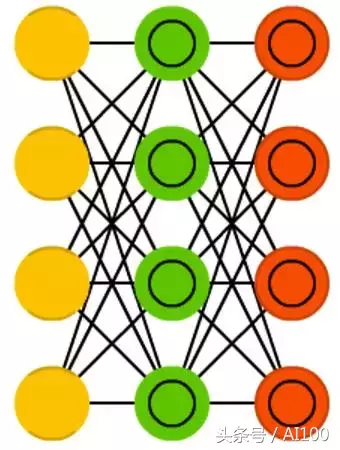
变分自编码机(VAE:Variational autoencoders)和AE有着相同的架构,却被教会了不同的事情:输入样本的一个近似概率分布,这让它跟BM、RBM更相近。
不过,VAE却依赖于贝叶斯理论来处理概率推断和独立(probabilistic inference and independence),以及重新参数化(re-parametrisation)来进行不同的表征。推断和独立非常直观,但却依赖于复杂的数学理论。基本原理是:把影响纳入考虑。如果在一个地方发生了一件事情,另外一件事情在其它地方发生了,它们不一定就是关联在一起的。如果它们不相关,那么误差传播应该考虑这个因素。这是一个有用的方法,因为神经网络是一个非常大的图表,如果你能在某些节点排除一些来自于其它节点的影响,随着网络深度地增加,这将会非常有用。
Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
https://arxiv.org/pdf/1312.6114v10.pdf
10、去噪自编码机(DAE)
去噪自编码机(DAE:Denoising autoencoders)是一种自编码机,它的训练过程,不仅要输入数据,还有再加上噪音数据(就好像让图像变得更加模糊一样)。
但在计算误差的时候跟自动编码机一样,降噪自动编码机的输出也是和原始的输入数据进行对比。这种形式的训练旨在鼓励降噪自编码机不要去学习细节,而是一些更加宏观的特征,因为细微特征受到噪音的影响,学习细微特征得到的模型最终表现出来的性能总是很差。
Vincent, Pascal, et al. “Extracting and composing robust features with denoising autoencoders.” Proceedings of the 25th international conference on Machine learning. ACM, 2008.
http://machinelearning.org/archive/icml2008/papers/592.pdf
11、深度信念网络(DBN)
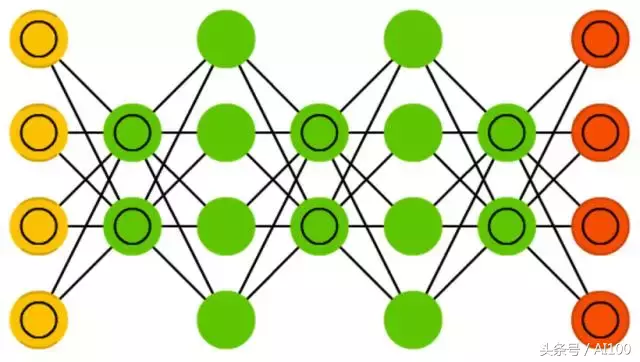
深度信念网络(DBN:Deep belief networks)之所以取这个名字,是由于它本身几乎是由多个受限玻尔兹曼机或者变分自编码机堆砌而成。
实践表明一层一层地对这种类型的神经网络进行训练非常有效,这样每一个自编码机或者受限玻尔兹曼机只需要学习如何编码前一神经元层的输出。这种训练技术也被称为贪婪训练,这里贪婪的意思是通过不断地获取局部最优解,最终得到一个相当不错解(但可能不是全局最优的)。可以通过对比散度算法或者反向传播算法进行训练,它会慢慢学着以一种概率模型来表征数据,就好像常规的自编码机或者受限玻尔兹曼机。一旦经过非监督式学习方式,训练或者收敛到了一个稳定的状态,那么这个模型就可以用来产生新的数据。如果以对比散度算法进行训练,那么它甚至可以用于区分现有的数据,因为那些神经元已经被引导来获取数据的不同特定。
Bengio, Yoshua, et al. “Greedy layer-wise training of deep networks.” Advances in neural information processing systems 19 (2007): 153.
https://papers.nips.cc/paper/3048-greedy-layer-wise-training-of-deep-networks.pdf
12、卷积神经网络(CNN)
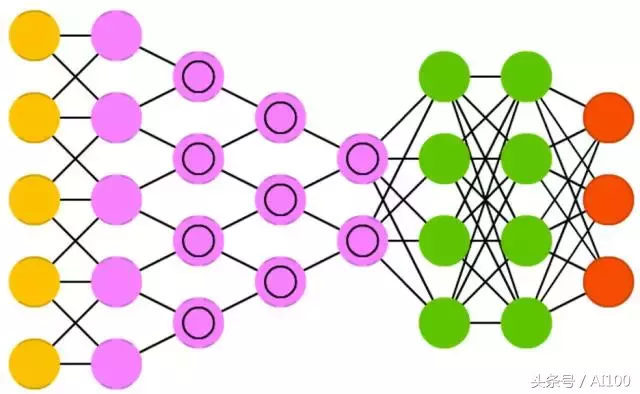
卷积神经网络(CNN:Convolutional neural networks)或深度卷积神经网络(DCNN:deep convolutional neural networks)跟其它类型的神经网络大有不同。它们主要用于处理图像数据,但可用于其它形式数据的处理,如语音数据。对于卷积神经网络来说,一个典型的应用就是给它输入一个图像,而后它会给出一个分类结果。也就是说,如果你给它一张猫的图像,它就输出“猫”;如果你给一张狗的图像,它就输出“狗”。
卷积神经网络是从一个数据扫描层开始,这种形式的处理并没有尝试在一开始就解析整个训练数据。比如:对于一个大小为200X200像素的图像,你不会想构建一个40000个节点的神经元层。而是,构建一个20X20像素的输入扫描层,然后,把原始图像第一部分的20X20像素图像(通常是从图像的左上方开始)输入到这个扫描层。当这部分图像(可能是用于进行卷积神经网络的训练)处理完,你会接着处理下一部分的20X20像素图像:逐渐(通常情况下是移动一个像素,但是,移动的步长是可以设置的)移动扫描层,来处理原始数据。
注意,你不是一次性移动扫描层20个像素(或其它任何扫描层大小的尺度),也不是把原始图像切分成20X20像素的图像块,而是用扫描层在原始图像上滑过。这个输入数据(20X20像素的图像块)紧接着被输入到卷积层,而非常规的神经细胞层——卷积层的节点不是全连接。每一个输入节点只会和最近的那个神经元节点连接(至于多近要取决于具体的实现,但通常不会超过几个)。
这些卷积层会随着深度的增加而逐渐变小:大多数情况下,会按照输入层数量的某个因子缩小(比如:20个神经元的卷积层,后面是10个神经元的卷积层,再后面就是5个神经元的卷积层)。2的n次方(32, 16, 8, 4, 2, 1)也是一个非常常用的因子,因为它们在定义上可以简洁且完整地除尽。除了卷积层,池化层(pooling layers)也非常重要。
池化是一种过滤掉细节的方式:一种常用的池化方式是最大池化,比如用2X2的像素,然后取四个像素中值最大的那个传递。为了让卷积神经网络处理语音数据,需要把语音数据切分,一段一段输入。在实际应用中,通常会在卷积神经网络后面加一个前馈神经网络,以进一步处理数据,从而对数据进行更高水平的非线性抽象。
LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.
http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf
13、解卷积网络(DN)
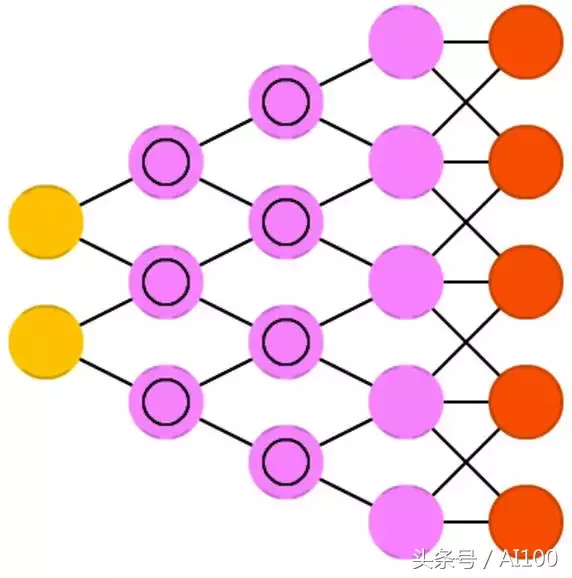
解卷积网络(DN:Deconvolutional networks),又称为逆图形网络(IGNs:inverse graphics networks),是逆向的卷积神经网络。
想象一下,给一个神经网络输入一个“猫”的词,就可以生成一个像猫一样的图像,通过比对它和真实的猫的图片来进行训练。跟常规CNN一样,DN也可以结合FFNN使用,但没必要为这个新的缩写重新做图解释。它们可被称为深度解卷积网络,但把FFNN放到DNN前面和后面是不同的,那是两种架构(也就需要两个名字),对于是否需要两个不同的名字你们可能会有争论。需要注意的是,绝大多数应用都不会把文本数据直接输入到神经网络,而是用二元输入向量。比如<0,1>代表猫,<1,0>代表狗,<1,1>代表猫和狗。
CNN的池化层往往也是被对应的逆向操作替换了,主要是插值和外推(基于一个基本的假设:如果一个池化层使用了最大池化,你可以在逆操作的时候生成一些相对于最大值更小的数据)。
Zeiler, Matthew D., et al. “Deconvolutional networks.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
http://www.matthewzeiler.com/pubs/cvpr2010/cvpr2010.pdf
14、深度卷积逆向图网络(DCIGN)
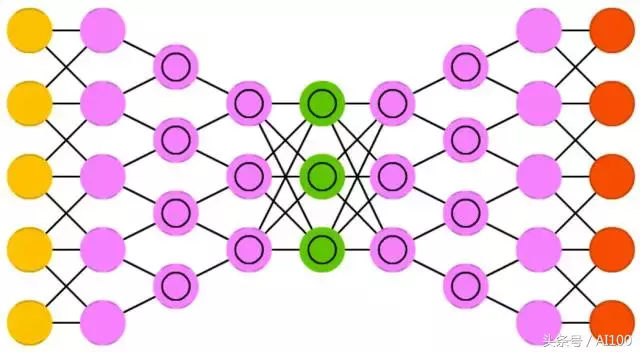
深度卷积逆向图网络(DCIGN:Deep convolutional inverse graphics networks),这个名字具有误导性,因为它们实际上是VAE,但分别用CNN、DNN来作编码和解码的部分。
这些网络尝试在编码过程中对“特征“进行概率建模,这样一来,你只要用猫和狗的独照,就能让它们生成一张猫和狗的合照。同理,你可以输入一张猫的照片,如果猫旁边有一只恼人的邻家狗,你可以让它们把狗去掉。很多演示表明,这种类型的网络能学会基于图像的复杂变换,比如灯光强弱的变化、3D物体的旋转。一般也是用反向传播算法来训练此类网络。
Kulkarni, Tejas D., et al. “Deep convolutional inverse graphics network.” Advances in Neural Information Processing Systems. 2015.
https://arxiv.org/pdf/1503.03167v4.pdf
转载网址:https://www.toutiao.com/i6432188985530909186/
原文链接:
http://www.asimovinstitute.org/neural-network-zoo/
http://www.asimovinstitute.org/neural-network-zoo-prequel-cells-layers/